
Introduction
Since ChatGPT was set loose on the world at the end of last year, the number of Large Language Models (LLMs) being released has increased dramatically. We are now seeing Open-Source models and other models that require significantly less power and hardware requirements – some can even be run locally on consumer-grade laptops (see GPT4ALL, for example).
I recently wrote an article about building an intelligent chatbot integrated with ChatGPT. But that is only one of the use cases for LLMs. Now, I want to look at another; a Creating an Intelligent Document Analyser chatbot that can analyse and answer questions related to a specific, pre-processed document.
New Concepts
Once again, this is a Proof of Concept (PoC) and is designed to demonstrate the capability of LLMs. This example uses a bounded context as the singular data source. It uses only one format and document to illustrate the possibilities. However, it should be easy to imagine how this can be scaled to include multiple formats over many files.
So, the Brief this time:
Build a Smart Q&A tool that allows for the upload of a PDF document, which is then subsequently used as the context for any queries a user enters. The solution is built on top of the previous PoC, reusing the integration with ChatGPT (i.e. the ‘chat’ functionality).
For smaller documents, this is a trivial exercise. Assuming the document is small enough, the content can be passed directly in the prompt to the model (specifying that this is the context to be queried). However, this is more complicated for oversized documents (and multiples thereof) due to the token limit.
For this to be achieved, several new concepts must be introduced: Embeddings and Vector Databases.
Embeddings
Embeddings are numerical representations of words, sentences or complete paragraphs in multi-dimensional vectors (e.g. an array of numbers). These representations capture semantic relationships, enabling algorithms and LLMs to understand and process the content.
Vector Databases
Vector databases are specialised databases for storing and retrieving high-dimensional vectors. They are optimised for similarity search and nearest neighbour queries and are commonly used in LLM applications. Note similarity searches match the semantics (the meaning) rather than on keywords.
Architecture and Design
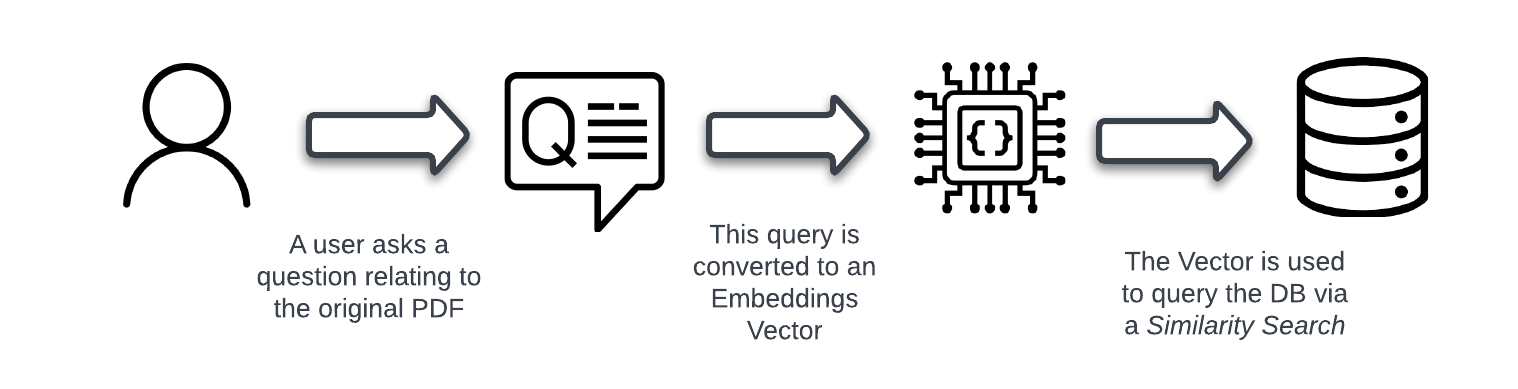
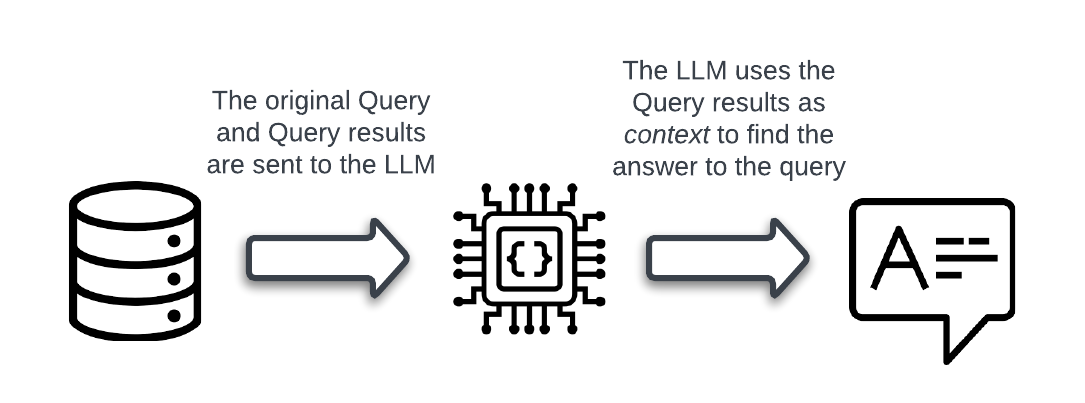
Let’s look at the high-level flow of how the user interacts with this application and how the application determines the answer to the query. It shows how and where those new concepts are used.
Process Flow
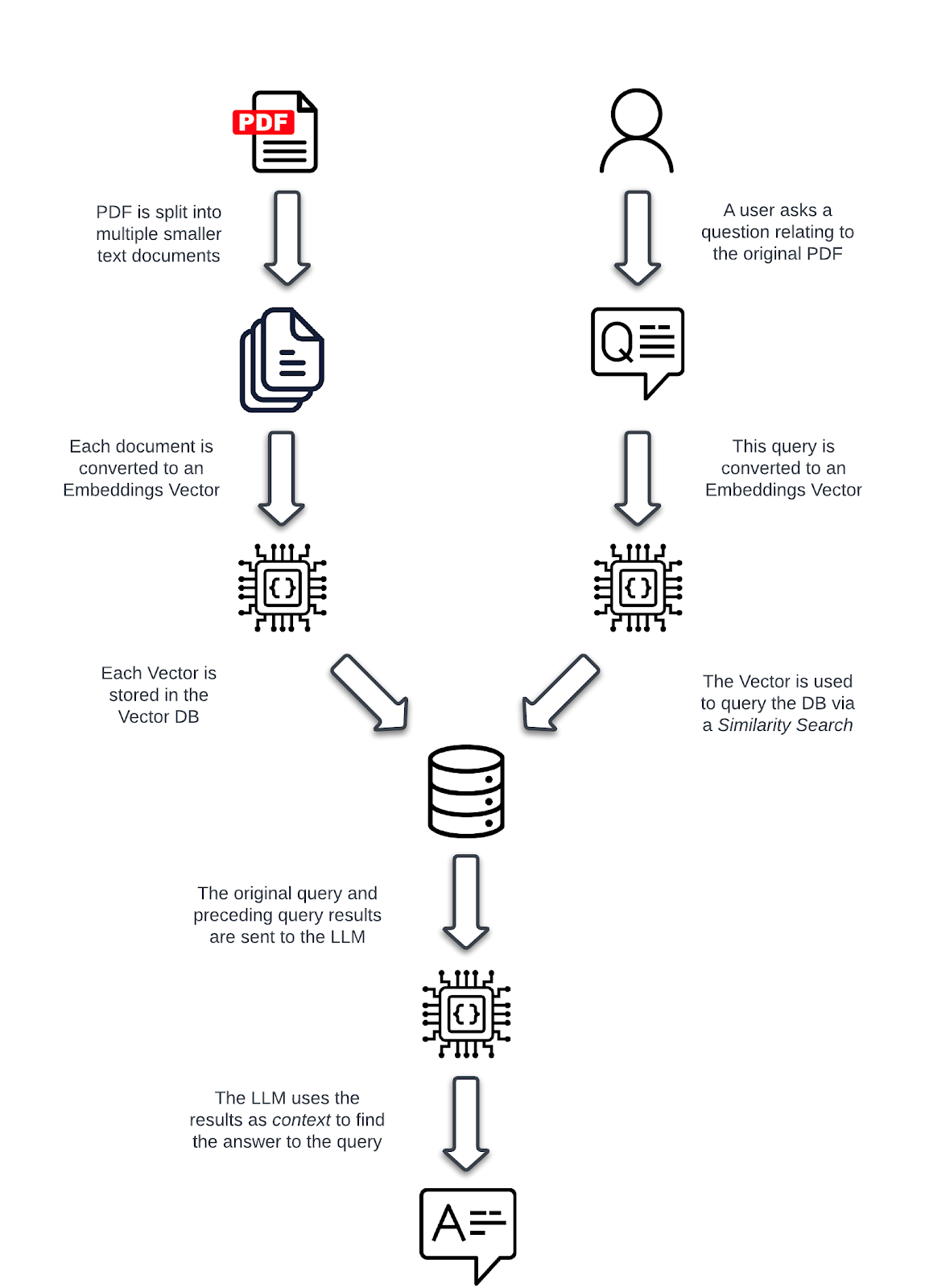
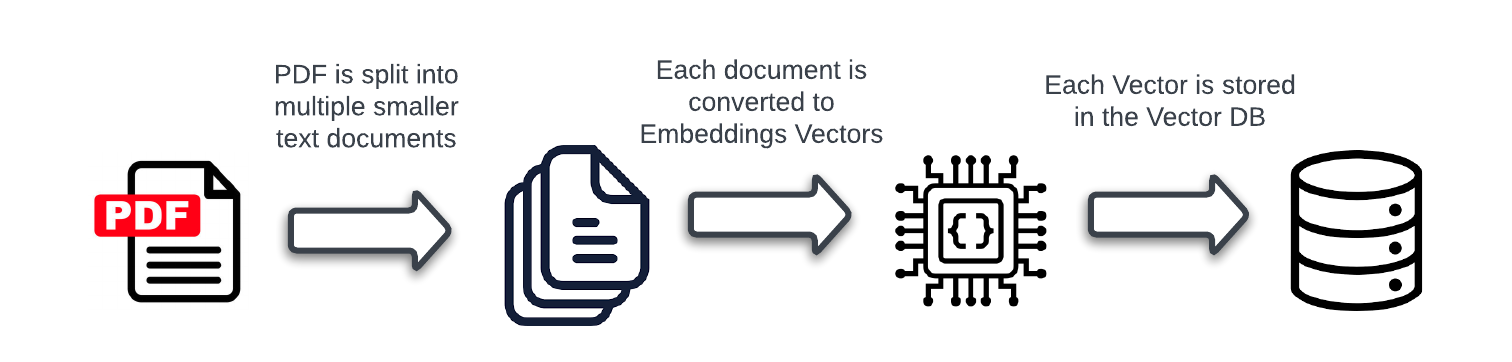
Before proceeding any further, let’s consider why we are chunking the document into smaller ones, as this isn’t immediately obvious.
- One issue is that although the PDF contains text, it is not plain text a computer can process – the textual element needs to be extracted from the PDF format.
- The other issue is the Token Limit (a limit on the total number of words that can be contained over the combined input and output). More extensive or multiple documents may exceed that threshold, stopping the model from being able to respond correctly.
Therefore, the text must be extracted and chunked to an appropriate size to overcome these issues.
Streamlight
A Python library called Streamlit has been used to create the GUI this time. This library is specifically for building data-science applications – so making a chatbot GUI is extremely simple.
OpenAI
Along with reusing the chat completions endpoint in the OpenAI API, the embeddings endpoint will also be used. The text (the document and the query) will be converted to numerical vectors by this endpoint.
The Embeddings endpoint is:
This POST endpoint accepts a JSON containing the text to be embedded (i.e. to be converted to a vector).
The API is well documented, so no further detail is provided besides a link to the API Reference page.
Pinecone
Pinecone is a cloud-based vector database with a free tier allowing users to have one Index (i.e. a single database). Several endpoints from the API will be used to store vectors and query the Index.
The API’s base URL is:
For this PoC, only POST endpoints are used, which accept JSON payloads.
Again, this API is well documented, so only a link to the API Reference page will be given.
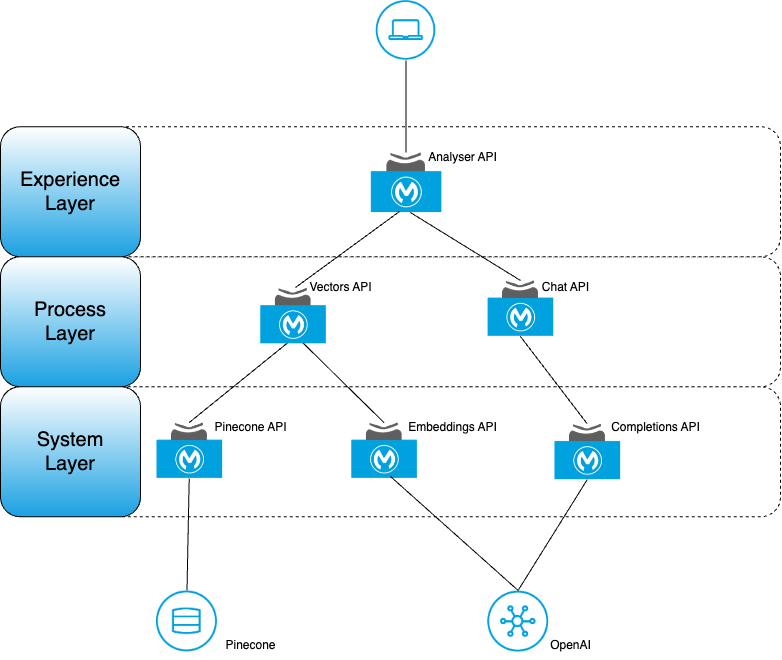
MuleSoft
So, applying the principles of API-Led Connectivity and reusing the appropriate APIs from the previous PoC, the diagram below shows the high-level Application Network.
Building the Document Analyser
Having chosen Streamlit to build the GUI, creating a multipage app is a straightforward process – with tabs on the left sidebar to select a relevant page (or function).
Welcome
The Welcome page will feel very reminiscent of the original chatbot. The same graphics have been reused to give a feeling of consistency. It can be customised as required but has been kept relatively simple in this PoC.

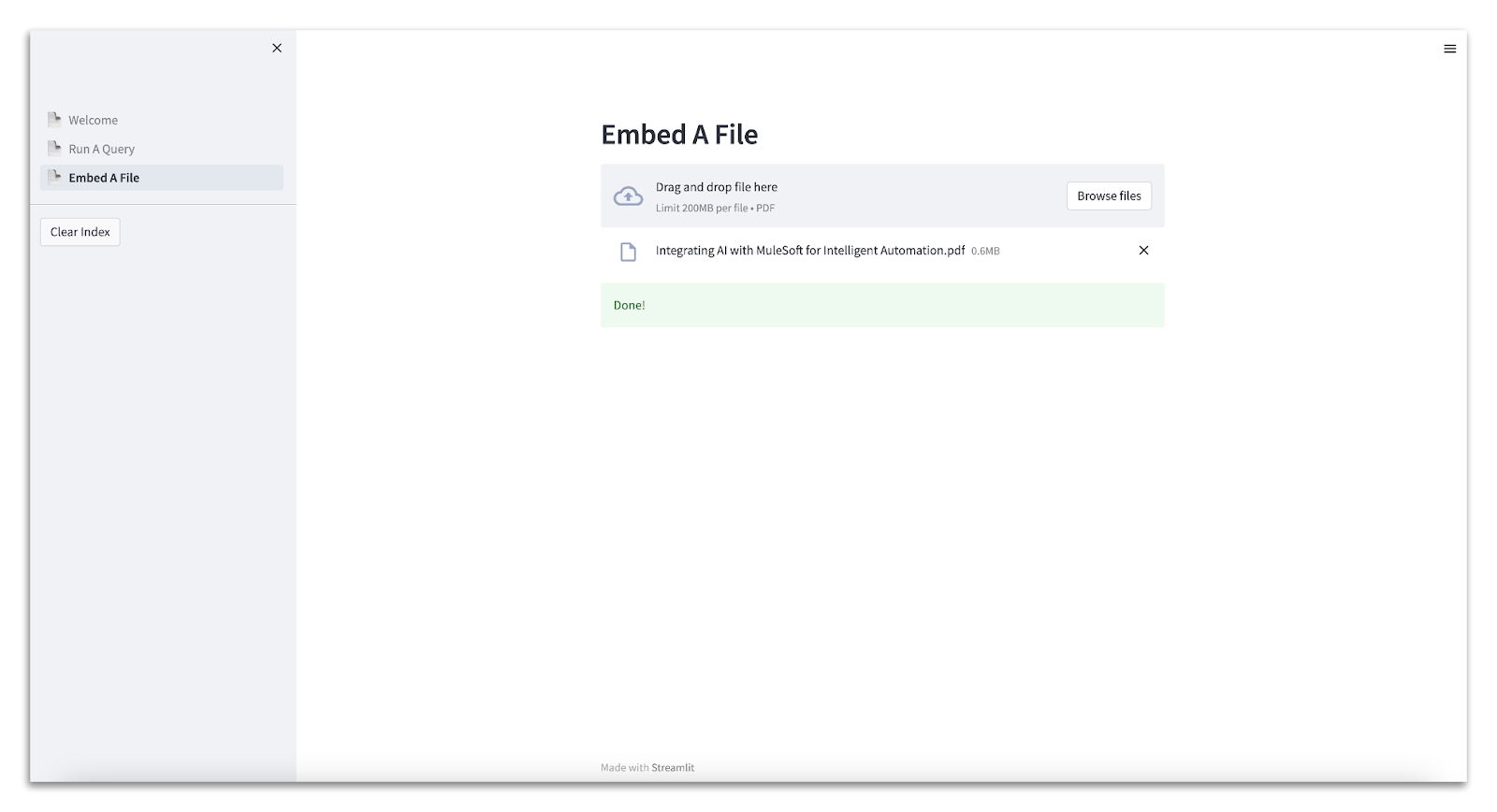
Embedding a File
The first step in being able to query a document is to chunk and embed it, then store the resulting vector representations for later querying, all done by calling the new Vectors Process API.
The screen has a file upload widget that confirms when the embedding process is complete. For this PoC, the source document is this whitepaper in PDF format (as shown in the screenshot).
Running a Query
A user enters their question via the chat interface to run a query against the document.
Once the Vector database has been queried, the returned context and the original query are passed to the LLM using the existing Chat Process API.
Question 1
A simple question is first asked to test the Q&A capabilities of the chatbot. This question has a specific answer and can be found in the document. The app locates it without any problems.

Question 2
Now, a more complex question is asked to stretch the app. This question requires the app to pick out a much more detailed answer and summarise it. Again, the app completes it without any issues.

Conclusion
We now have a simple Q&A chatbot that can be used to query an uploaded PDF document. Being a PoC, it’s a relatively simple app; it can only query a single PDF document.
The next step in enhancing the app would be to allow multiple documents of different formats to be queried, making the app truly useful. Another vital enhancement, though not demonstrated here, would be the ability for users to ask follow-up questions based on the preceding chat history. It may seem like a minor issue. Still, technically, it requires the correct context for all questions to be retained, meaning any follow-up questions themselves need rewriting as complete, standalone questions before being initially embedded.
Another task would be to investigate the use of Open-Source LLMs. As I said earlier, these are much cheaper, requiring much lower computing requirements. I’ll look at these in my next article in this series.
Final Thoughts
Over this series of articles, we’ve been using LLMs to create intelligent chatbots. The first used its knowledge to answer questions, and the second used external documents to provide answers.
Hopefully, it’s easy to see the use cases of such technology. Searching through large numbers of documents or webpages at speed would be highly advantageous to any user, either individuals or larger organisations.
If we consider the amount of data and information currently inaccessible due to processing and retrieval difficulties, technology like this can extract essential details and provide valuable insights.
It will become an essential tool in the future (sooner rather than later) as it becomes cheaper and more accessible, with ethical and privacy issues being resolved. Allowing everyone faster access to information and those who can use it will be at a significant advantage.
If you would like to discover how AI could be integrated into your business, don’t hesitate to get in touch with one of our experts.

